web.xml中的url-pattern详解
一、先精确匹配,再路径匹配
(路径匹配的时候,先最长路径匹配,再最短路径匹配),至于扩展名匹配,就是单独于精确匹配和匹配的一类了,以上都找不到servlet,就用默认的servlet,配置为/。
二,servlet容器对url的匹配过程:
当 一个请求发送到servlet容器的时候,容器先会将请求的url减去当前应用上下文的路径作为servlet的映射url,比如我访问的是 http://localhost/test/aaa.html,我的应用上下文是test,容器会将http://localhost/test去掉, 剩下的/aaa.html部分拿来做servlet的映射匹配。这个映射匹配过程是有顺序的,而且当有一个servlet匹配成功以后,就不会去理会剩下 的servlet了(filter不同,后文会提到)。其匹配规则和顺序如下:
1. 精确路径匹配。例子:比如servletA 的url-pattern为 /test,servletB的url-pattern为 /* ,这个时候,如果我访问的url为http://localhost/test ,这个时候容器就会先进行精确路径匹配,发现/test正好被servletA精确匹配,那么就去调用servletA,也不会去理会其他的 servlet了。
2. 最长路径匹配。例子:servletA的url-pattern为/test/*,而servletB的url-pattern为/test/a/*,此 时访问http://localhost/test/a时,容器会选择路径最长的servlet来匹配,也就是这里的servletB。
3. 扩展匹配,如果url最后一段包含扩展,容器将会根据扩展选择合适的servlet。例子:servletA的url-pattern:*.action
4. 如果前面三条规则都没有找到一个servlet,容器会根据url选择对应的请求资源。如果应用定义了一个default servlet,则容器会将请求丢给default servlet(什么是default servlet?后面会讲)。

web系统的具体起源都是什么?
1989年CERN(欧洲粒子物理研究所)中由Tim Berners-Lee领导的小组提交了一个针对Internet的新协议和一个使用该协议的文档系统,该小组将这个新系统命名为World Wide Web,它的目的在于使全球的科学家能够利用Internet交流自己的工作文档。
这个新系统被设计为允许Internet上任意一个用户都可以从许多文档服务计算机的数据库中搜索和获取文档。1990年末,这个新系统的基本框架已经在CERN中的一台计算机中开发出来并实现了,1991年该系统移植到了其他计算机平台,并正式发布。
上一篇:网络编程基础的常用协议都什么?在计算机系统中的机器语言是?
下一篇:最后一页
- web.xml中的url-pattern详解是?web系统的具体起源都是什么?
- 网络编程基础的常用协议都什么?在计算机系统中的机器语言是?
- 服务器监控的目标都有什么?其他服务器监控方案都是什么?
- 乡镇卫生院财务个人总结报告-乡镇卫生院财务个人总结_环球今亮点
- HG255d的设计图纸是?平面图的具体定义是什么?
-
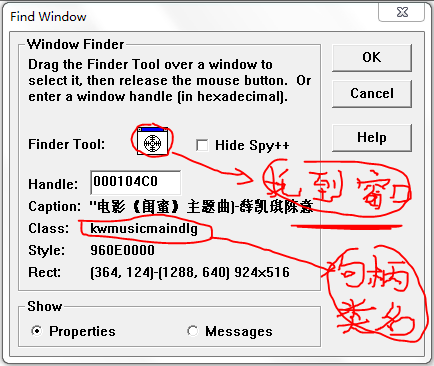
首先打开VC或者VS里面tool中的SPY++点击是?音梳音数的具体含义是?
首先打开VC或者VS里面tool中的SPY++点击查找窗口如下:PS:把那个靶心似的的东西移动到想查找的窗口上,这里是酷我音乐盒,下面会出现窗口 -

如何定义服务器监控都是什么意思?WINDOWS XP的服务器监控是?
如何定义服务器监控企业运行多个服务器来为其最终用户交付业务关键服务。其中包括数据库服务器、核心应用服务器、缓存服务器、web服务器等 -

常用的表单元素都有什么?表单元素事件属性是什么意思?
常用的表单元素form: 定义供用户输入的表单。fieldset: 定义域。即输入区加有文字的边框。legend:定义域的标题,即边框上的文字。label -

环球通讯!世行:全球老龄化速度之快前所未有,多国对劳动力的竞争日趋激烈
该报告研究显示,许多国家未来几十年的成年劳动力占比将大幅下降。 -

每日精选:浙农股份:公司将在4月27日披露2022年度报告,相关业绩情况届时请关注查询定期报告
浙农股份(002758)04月26日在投资者关系平台上答复了投资者关心的问题。 -

我国迁地保护长江江豚首次放归长江
4月25日,来自长江天鹅洲故道的4头迁地保护长江江豚分批顺利放归进入长江干流新螺和石首江段。这是在长江流 -

证监会四方面推动REITs市场健康平稳运行 每日热讯
证监会四方面推动REITs市场健康平稳运行,立法,证监会,周小舟,reits,证券及期货事务监察委员会 -

大悦城控股2022年营业收入395.79亿元 归母净亏损28.83亿元-每日观察
4月25日,大悦城控股集团股份有限公司发布2022年年度报告。观点新媒体获悉,数据显示,2022年该公司实现营 -

还可以使用crunch来生成密码?柯林斯双解crunch是?
还可以使用crunch来生成密码crunch默认安装在kali环境中(05-Password Attacks),Crunch可以按照指定的规则生成密码字典,生成的字典字符序 -

class反编译该怎么进行处理?class的使用方法都是什么?
class反编译背景:前几天在项目开发的时候遇到一个问题,那就是利用myeclipse编写好的一个项目打包成jar包后上传部署到服务器里,之后本地


